|
Big Data - a term that has become very trendy during previous years. Everyone who works with data in some way knows the term, and yet there are still uncertainties about what Big Data actually is and how we should cope with it. In this blog post, we will elaborate on the reasons why the term “Big Data” not only refers to increased volumes of data but its scope. We will therefore not only address its definition but also its potential, challenges, and the reason why it will fundamentally change the way we see our world. What is Big Data? In common terms, Big Data is defined by using the famous three V’s:
The three V’s can be extended with ‘Veracity’ and ‘Variability’, while the former refers to the varying quality of data and the latter describes the irregular, unpredictable streams of incoming data. What’s behind the hype? The hype behind Big Data can be explained by looking at three main dimensions; the proceeding disaggregation of data, the increased computer processing capacity, and the more powerful data analysis methods available. 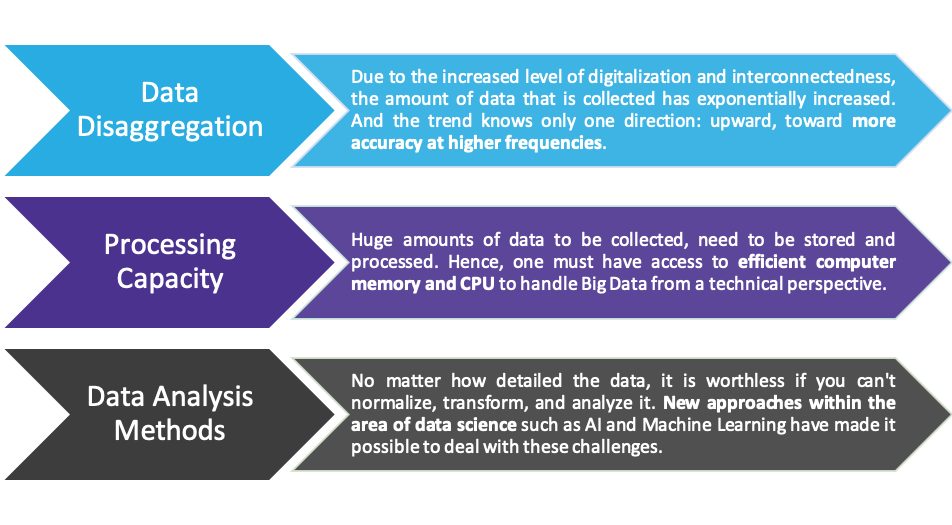 During recent years, interconnected digitalization has led to enormous amounts of data that is collected every day. In fact, we created 912.5 quintillion data bytes in 2020 which equals 2.5 billion Gigabytes per day (source: Domo, 2021). Where is all this data coming from? Today, most of us carry smart phones and they are constantly collecting and generating data by monitoring our location, measuring our speed, tracking what apps we are using as well as who we are calling or texting.
Social networks collect what formerly had been conversations: Twitter, Facebook, Instagram and TikTok store multiple terabytes (1’000 GB) of data every day (e.g. Twitter: 12 terabytes daily) and 300 hours of video uploaded to YouTube every minute. Moreover, we increasingly use gadgets and sensors to capture and measure everything from temperature to power consumption, from store visits to traffic flows, from body composition to heart rates. Hence, not only the amount of data that we are collecting has increased enormously but also the attention to detail when we look at it, namely the level of disaggregation. We have changed the way we measure the world. And that’s why we should also change the way we look at it. Fortunately, we nowadays have a broad set of technical capabilities for storing and processing these enormous volumes of data. Whereas a few years ago it would have been necessary to make large investments in on-site hardware, today the necessary resources can be accessed flexibly. On one-hand, computer memory has become generally much cheaper and easier to search through. On the other-hand, cloud computing has made it possible for businesses to flexibly scale their data storing and processing capacities, making it possible to significantly reduce investment costs required upfront. Besides the trend of increasing data amounts and the associated higher demands on technology, there is a third dimension that must keep up with this evolution: These are the methods that we apply to normalize, transform, and analyze data. While traditional data is mostly measured in pre-determined structures, Big Data can appear in various formats. As an example, imagine IoT devices that measure various environmental conditions at millisecond intervals and thus have to constantly link their digital environment with the real world. This couldn’t be done without fast and fully automated data transformation flows. Additionally, Artificial Intelligence (AI) and Machine Learning (ML) make it possible for us humans to act on this data, to recognize trends and to draw our conclusions from them. To conclude, working with big data enables firms to massively leverage their data insights. It has become possible to more accurately predict human behavior, make faster and better business decisions, reach higher productivity levels, and as a result, to gain higher profits. More and more firms, both big and small, are thus trying to benefit from Big Data applications. However, these benefits do not come without potential pitfalls, which we address in the following section. Challenges of Big Data Nowadays we don’t have the problem of scarce data anymore. The opposite is the case - we need to carefully define which data set might be insightful for us and how to combine different kinds of data. The use of Big Data poses various challenges caused by its volume, velocity and variety. A first obvious challenge is setting up an appropriate IT infrastructure. This involves providing adequate software and creating a data lake combined with a data warehouse, in order to pool different kinds of data. A data lake is basically a dump to store all raw data, whereas a data warehouse is used to model relationships and to filter & transform data to be analyzed in a dashboard. Setting up the infrastructure might involve high up-front costs. But the effort of adding and maintaining data is much lower, we promise. Related to the use of new technologies and methodologies also requires solid human capital. A modern technology stack means that there are few people who are experienced with the tools, which makes it hard to find good candidates. A popular method to get a lot of data at low cost is web scraping. However, this method raises legal issues with regard to privacy and ethics. Moreover, for some firms, data is not allowed to cross borders. This regulation sets a constraint on the cloud server that is used. Effective data and identity management policies ensure the privacy of sensitive information (e.g. personal consumer and customer data) and avoid data being used for unintended purposes. Whether data is big or small, structured or unstructured, on premises or in the cloud, the need for data quality doesn’t change. Unfortunately, the path to clean data might become a rocky one. Big data platforms often end up with the same data loaded multiple times. Therefore it’s important to find the right approach to deduplicate data. Also, data from different sources usually have different business keys for the same business object. For example, a customer number in your CRM source system might be different to the customer number in your invoicing system, but the customer is actually the same. Furthermore, assume you are using Google or Twitter searches to generate data. The general rule is: The more data the more accurate your results. But obviously it’s impossible to load all data available in this universe which makes data sampling essential. The challenge therefore is to find a balance between accurate results and quickly running models. Moreover, defining a good data sample is crucial for algorithmic fairness. When building an algorithm, we classify data based on the information provided in the data set. As you can imagine, there is a danger of biased results classifying sensitive data, for example in relation to health condition or trade-union membership. Big data projects can be very expensive, if not managed correctly. The storage and computation of data, the combination of low quality data and limited experience as well as changing business requirements make it challenging to stay within a constrained budget. Conclusion Recent advances in the area of data disaggregation, computer processing capacities, and data analysis methods have changed the way we measure the world. The term Big Data, which has emerged from these developments, is therefore not only about handling high volumes of data. Rather, it’s about flexibility and being able to scale up data processing methods in terms of complexity and variety - no matter how chaotic, versatile and fast the data is flowing into your system. Hence, you should consider the challenges Big Data brings up and optimize your IT infrastructure to fit its needs. Moreover, there are further challenges with regard to human capital, legal, and last but not least, the ensurement of data quality among all different layers.
0 Comments
Your comment will be posted after it is approved.
Leave a Reply. |
Categories
All
Archives
March 2023
Subscribe to our newsletter |
 RSS Feed
RSS Feed
BI Concepts GmbH
Oberdorfstrasse 13
8808 Pfäffikon
Switzerland
Swiss Commercial Register Entry
VAT No (UID): CHE-434.247.552
(founded in 2020)
Privacy Policy
Oberdorfstrasse 13
8808 Pfäffikon
Switzerland
Swiss Commercial Register Entry
VAT No (UID): CHE-434.247.552
(founded in 2020)
Privacy Policy