|
We recently shared our very first dataset on the Snowflake Marketplace, and we couldn't be more thrilled about it. Best of all, it's free for all Snowflake customers to use! Our priority was to make the data loading process into Snowflake as cost-efficient as possible while providing users with the most value. This kickstarted our analysis of Snowflake data loading, and we've got some interesting insights to share with you. Let's dive in!  Snowflake offers several features for loading data into its system. Snowpipe is the common approach if data should be available to users as soon as it is available. What is Snowpipe? Snowpipe is Snowflake’s continuous data ingestion service that loads data within minutes after files are added to a stage and submitted for ingestion. With Snowflake’s serverless compute model, it ensures optimal compute resources and ensures that load capacity is managed. Snowpipe provides a pipeline for loading fresh data in micro-batches as soon as it is available. Supported Cloud Storage Services for Snowpipe The following table indicates the cloud storage service support for automated Snowpipe from Snowflake accounts hosted on each cloud platform:  Setup for the Cost Analysis To begin our analysis, we started with Amazon S3 as our preferred cloud storage service. In order to use Snowpipe in an automated way, we created a new Snowflake account in the Amazon Web Services (AWS) public cloud since we only had Azure-based accounts in our organization. Next, we wanted to compare the cost difference between using manual Snowpipe updates versus automated updates since our dataset was only updated once a day. We considered two options - firstly, using the same storage location and updating Snowpipe manually every day. Alternatively, we were curious to know if putting the files into an internal stage in Snowflake would reduce costs, given that data loading from an internal stage is usually faster than from an external storage location like Amazon S3. Three Methods for Loading Data into Snowflake with Snowpipe We will compare the cost for the following three methods for loading data into Snowflake:
Automated Snowpipe from S3 Automated Snowpipe uses event notifications from cloud storage to notify Snowpipe when new data files arrive. These files are then copied into a queue and loaded into the target table in a continuous and serverless manner. 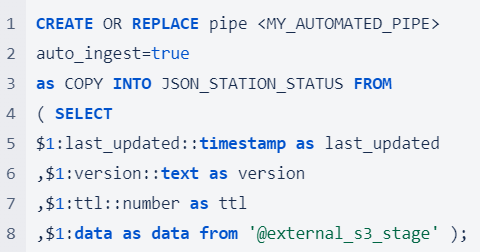 Manual Snowpipe from S3 However, automated Snowpipe does not work for every Snowflake account host and cloud provider. At present, cross-cloud support is limited to accounts hosted on Amazon Web Services. If your account is hosted on Google Cloud Platform (GCP) or Microsoft Azure, automated Snowpipe can only be used with the same cloud storage provider. If you are using two different cloud providers, you can still use Snowpipe, but you will need to execute an additional command to refresh the pipe and load the data. We refer to this as Manual Snowpipe. 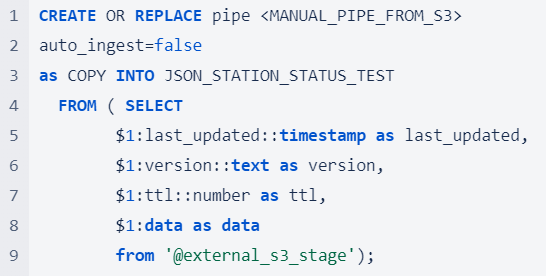 For a long-term, productive solution, using the REST API is the recommended approach to detect and load new files. In this cost comparison, we used the following refresh command for the sake of simplicity.  Manual Snowpipe from Internal Stage (Python Snowflake Connector) The Python Snowflake Connector offers an interface that connects to Snowflake and enables the execution of all standard operations. To put files into an internal stage, all we needed to do was set up a connection to our Snowflake account and run the following command:  After putting the file to the internal stage, Snowpipe comes into play. 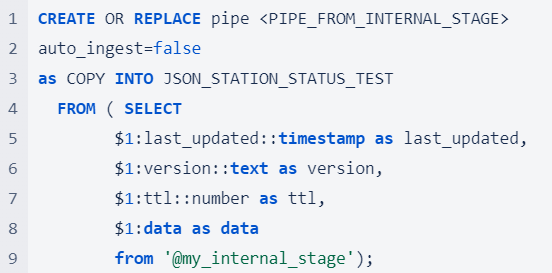 Automated Snowpipe is not supported for internal stages, so we need to run the refresh command again. 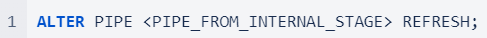 The Cost and Benefit Comparison of the Three Data Loading MethodsHow We Compared The Costs
*Prefect is a platform for automating data workflows, similar to Airflow Assumption: A Snowflake Standard Account hosted on AWS in Frankfurt. The Breakdown of the Monthly Costs for Each Method The Manual Snowpipe from Internal Stage using the Python Snowflake Connector is the most cost-effective method for loading data into Snowflake among the three methods (Automated Snowpipe, Manual Snowpipe from S3 and Manual Snowpipe from internal stage), as it had the lowest total monthly cost of 16.08 CHF, with only minimal costs incurred for Snowflake credits and VM costs of 15 CHF monthly. 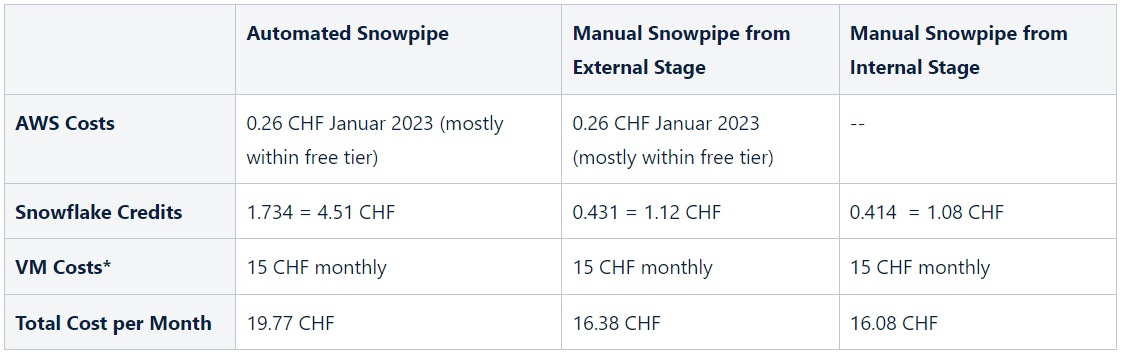 *Normally, Virtual Machine (VM) costs are shared across various workflows. This scenario assumes we only have one job to run on the VM. 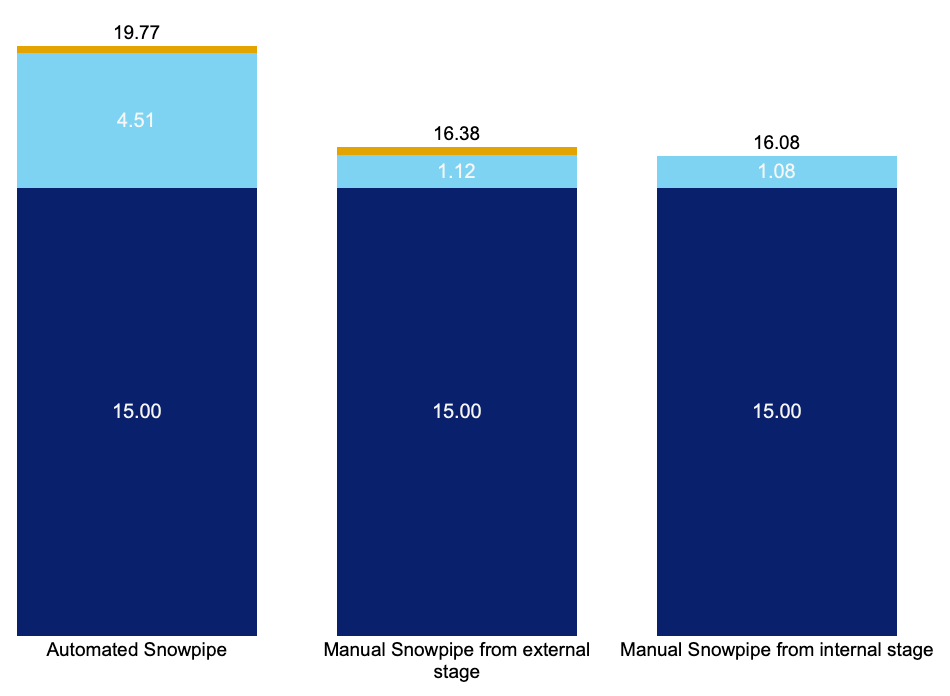 Advantages and Disadvantages of Three Different Snowpipe Methods In terms of advantages, Automated Snowpipe is fully managed and works with any cloud provider. Manual Snowpipe also works with any cloud provider, but an additional refresh command is required. The Python Snowflake Connector allows the file to be put into the internal stage, which improves performance, but there is no persistent storage area and it requires more effort to write commands in Python. 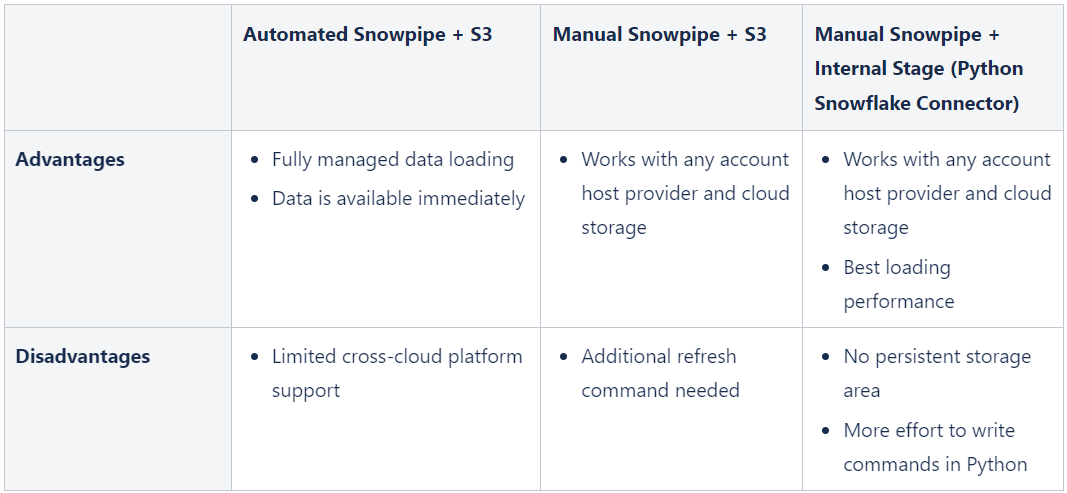 Conclusion of the ComparisonIn conclusion, each method has its own benefits and drawbacks, and the best method to use depends on the specific use case. Whether you are looking for fully managed data loading with immediate data availability or a cost-optimised data loading approach, Snowflake has the solution for you.
Let us help you find the best solution for you to maximise the potential of your data. Get in touch now!
0 Comments
Your comment will be posted after it is approved.
Leave a Reply. |
Categories
All
Archives
March 2023
Subscribe to our newsletter |
 RSS Feed
RSS Feed
BI Concepts GmbH
Oberdorfstrasse 13
8808 Pfäffikon
Switzerland
Swiss Commercial Register Entry
VAT No (UID): CHE-434.247.552
(founded in 2020)
Privacy Policy
Oberdorfstrasse 13
8808 Pfäffikon
Switzerland
Swiss Commercial Register Entry
VAT No (UID): CHE-434.247.552
(founded in 2020)
Privacy Policy